레플리케이션(Replication), 클러스터링(Clustering), 샤딩(Sharding)
셋 모두 여러곳에서 사용하는 단어이지만
본 포스팅에서는 DB에 관련하여 설명합니다.
진행중인 프로젝트
MySQL - Replication(부하 분산) 적용, Redis - Clustering(Active - Standby) 적용
GitHub - Hwangwonuk/cucumber-market: 중고물품 거래사이트 오이마켓 토이프로젝트
중고물품 거래사이트 오이마켓 토이프로젝트. Contribute to Hwangwonuk/cucumber-market development by creating an account on GitHub.
github.com
개요
Sharding, Clustering, Replication의 공통점
데이터 베이스를 여러개로 만든다.
기본적인 데이터베이스

데이터베이스는 실제 요청을 처리하는 데이터베이스 서버와
데이터가 저장되는 스토리지를 가지고 있습니다.
클러스터링(Clustering)
데이터 베이스 서버가 죽으면 어떻게 해야하는가?
-> 클러스터링이 나오게된 배경
가장 간단하게 생각한것이 데이터베이스 서버를 여러개로 만들자! 입니다.
이 방법이 바로 클러스터링 입니다.
Active - Active 클러스터링
서버를 여러개로 구성하고 모든 서버를 Active 상태
즉, 실제로 동작하는 상태로 만드는것을 말합니다.
장점
1. 하나의 서버가 죽더라도 다른 하나가 그 역할을 대신할 수 있기 때문에
서버의 중단 없이 서비스가 지속적으로 운영됩니다.
2. 서버 두 대가 운영되기 때문에 CPU나 Memory를 더 많이 사용할 수 있습니다.
즉, 성능적인 측면에서 이득을 볼 수 있습니다.
단점
1. 스토리지는 하나를 공유하기 때문에 병목현상이 발생합니다.
2. 두 서버를 운영해야 하기때문에 비용이 비쌉니다.
Active - Standby 클러스터링
서버를 여러개로 구성하고 하나의 서버를 Active상태로 두고
다른 하나의 서버는 standby 상태로 대기시킵니다. -> 실제 동작X
이후 Active 서버에 문제가 발생한다면
Standby 서버를 Active 서버로 전환하는 방식으로 구현합니다.
단점
Standby 서버는 실제로 운영되지 않기때문에 Active 상태에서 문제가 발생하면
이를 정화하는데 시간이 오래 걸립니다.
장점
실제로 운영을 하지않아도 되기 때문에 Standby를 사용하면
서버 비용을 절감할 수 있습니다.
레플리케이션(Replication)
저장된 데이터가 손실되면 어떻게 해야하는가?
하나의 서버가 중단된다면 클러스터링으로 해결되지만,
스토리지는 하나이기 때문에 문제를 해결하기 위해서
실제 데이터가 저장되는 저장소도 복제해야 합니다.
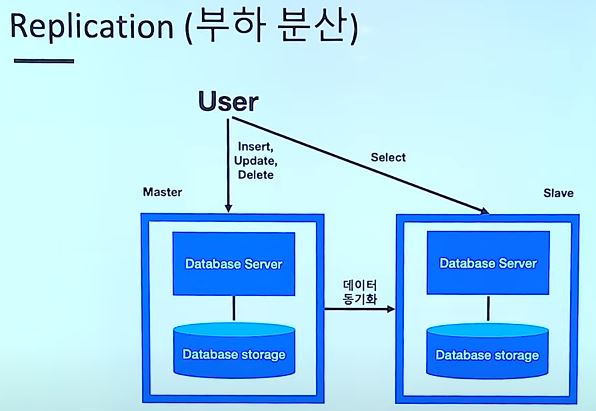
기본적인 Replication의 구조는 Master - Slave 구조로 나누어집니다.
Master DB에 CRUD과정을 거치면 그 데이터를
Slave에 동기화 시켜서 데이터를 백업하는 용도로 사용합니다.
더 나아가서 Slave DB를 백업용으로만 사용하기엔 낭비이기에
Slave DB를 Read용도로 나누어 부하 분산의 용도로 사용합니다.
샤딩(Sharding)
데이터가 너무 많아서 검색이 느린데 더 빠르게 할 수 있는 방법은 없는가?
테이블을 나눠서 검색해보자! 라는것이 샤딩입니다.

위와같은 테이블이 있는데
샤딩은 테이블을 row단위로 나누어서 각각의 샤드에 적용하는 역할을 합니다.
그래서 데이터를 검색할 때 데이터가 어느 샤드에 있는지만 알게되면
검색 속도가 향상됩니다.
샤딩 테이블 구성시 고려할 사항
1. 분산된 Database에 Data를 어떻게 잘 분산시켜서 저장할 것인가?
2. 분산된 Database에서 Data를 어떻게 읽을 것인가?
Shard key
나눠진 Shard중 어떤 Shard를 선택할지 결정하는 키입니다.
Shard key 결정 방식에 따라 Sharding 방법이 나누어집니다.
1. Hash Sharding
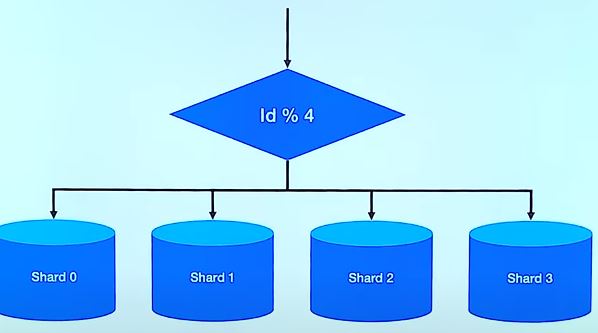
위 이미지에서 Shard0 , 1, 2, 3이 바로 Shard Key 입니다.
Shard Key 결정하는데 있어서 Hash 함수를 사용하는것이 Hash Sharding 방식입니다.
장점
구현 자체가 샤드의 수많큼 해싱을 하면 되기때문에 간단합니다.
단점
샤드의 수가 늘어나면 해시함수 자체가 변경되어야 하기때문에 기존에 저장되었던
데이터들에 대한 정합성이 깨지게 됩니다.
-> 확장성이 좋지않음
단순히 키를 기준으로 데이터를 나누기 때문에
공간에 대한 효율성을 고려하지 않고 단순히 해시로만 처리합니다.
2. Dynamic Sharding
확장성을 해결하기 위해 나온것이 바로 Dynamic Sharding 입니다.

Locator service라는 테이블 형식의 구성요소를 가지고
샤드키를 결정하는 방식입니다.
따라서, 샤드가 추가되어도 Locator service에 샤드키만 추가하는 방식으로
확장성을 보장합니다.
단점
Locator service에 나머지 샤드들이 종속적이기 때문에 Locator service에 문제가 생기면
나머지 샤드들 모두 문제가 생기게 됩니다.
3. Entity Group
앞에서 말한 1, 2번의 경우에는 관계형 데이터베이스 보다는
key - value 형식인 No-SQL에 더 적합한 샤딩방식 입니다.
그래서 나온것이 Entity Group 입니다.

관계가 되어있는 Entity를 같은 샤드내에 공유하도록 만드는 방식입니다.
장점
단일 샤드내에서 쿼리가 효율적이다.
단일 샤드내에서 강한 응집도를 가진다.
단점
다른 샤드의 Entity와 연관이 되는 경우 비효율적이다.
마무리
데이터 베이스를 나누는 것도 다 비용이기 때문에
현재 상황에 맞는 기술을 활용하는 것이 중요합니다.
특히, 샤딩같은 경우에는 매우 복잡하기 때문에
오히려 우선 캐싱을 사용하여 성능향상을 생각하고
나중에 샤딩을 적용하는 방법이 있습니다.
MySQL에서의 레플리케이션, 클러스터링
레플리케이션 이란?
여러개의 DB를 권한에 따라 수직적인 구조(Master-Slave)로 구축하는 방식입니다.
리플리케이션에서 Master Node는 쓰기 작업 만을 처리하며 Slave Node는 읽기 작업만을 처리합니다.
리플리케이션은 비동기 방식으로 노드들 간의 데이터를 동기화 합니다.
레플리케이션 처리방식
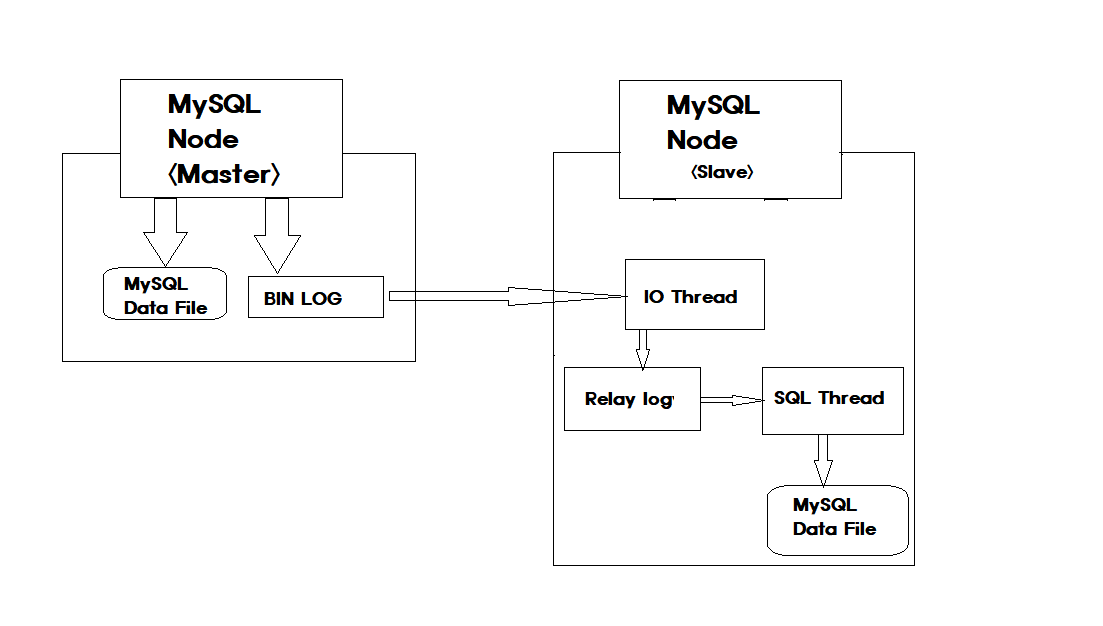
1. Master 노드에 쓰기 트랜잭션이 수행된다.
2. Master 노드는 데이터를 저장하고 트랜잭션에 대한 로그를 파일에 기록한다.(BIN LOG)
3. Slave 노드의 IO Thread는 Master 노드의 로그 파일(BIN LOG)를 파일(Replay Log)에 복사한다.
4. Slave 노드의 SQL Thread는 파일(Replay Log)를 한 줄씩 읽으며 데이터를 저장한다.
레플리케이션은 Master와 Slave간의 데이터 무결성 검사(데이터가 일치하는지)를 하지 않는 비동기방식으로
데이터를 동기화합니다.
레플리케이션(Replication) 장점과 단점
- 장점
- DB 요청의 60~80% 정도가 읽기 작업이기 때문에 Replication만으로도 충분히 성능을 높일 수 있다.
- 비동기 방식으로 운영되어 지연 시간이 거의 없다.
- 단점
- 노드들 간의 데이터 동기화가 보장되지 않아 일관성있는 데이터를 얻지 못할 수 있다.
- Master 노드가 다운되면 복구 및 대처가 까다롭다.
클러스터링(Clustering)이란?
클러스터링이란 여러 개의 DB를 수평적인 구조로 구축하는 방식이다.
클러스터링은 분산 환경을 구성하여 단일서버의 장애 대응불가 문제를 해결할 수 있는
Fail Over 시스템을 구축하기 위해서 사용된다.
클러스터링은 동기 방식으로 노드들 간의 데이터를 동기화하는데, 자세한 처리 방법은 아래와 같다.

위의 그림은 MySQL의 Clustering 방식 Galera 방식에 대한 그림이며 자세한 처리 순서는 아래와 같다.
- 1개의 노드에 쓰기 트랜잭션이 수행되고, COMMIT을 실행한다.
- 실제 디스크에 내용을 쓰기 전에 다른 노드로 데이터의 복제를 요청한다.
- 다른 노드에서 복제 요청을 수락했다는 신호(OK)를 보내고, 디스크에 쓰기를 시작한다.
- 다른 노드로부터 신호(OK)를 받으면 실제 디스크에 데이터를 저장한다.
클러스터링은 DB들 간의 데이터 무결성 검사(데이터가 일치하는지)를 하는 동기방식으로 데이터를 동기화한다. 이러한 구조에 의해 클러스터링 방식은 다음과 같은 장점과 단점을 갖고 있다.
클러스터링(Clustering) 장점과 단점
- 장점
- 노드들 간의 데이터를 동기화하여 항상 일관성있는 데이터를 얻을 수 있다.
- 1개의 노드가 죽어도 다른 노드가 살아 있어 시스템을 계속 장애없이 운영할 수 있다.
- 단점
- 여러 노드들 간의 데이터를 동기화하는 시간이 필요하므로 Replication에 비해 쓰기 성능이 떨어진다.
- 장애가 전파된 경우 처리가 까다로우며, 데이터 동기화에 의해 스케일링에 한계가 있다.
클러스터링을 구현하는 방법으로는 또 Active-Active와 Active-Standby가 있다.
Active-Active는 클러스터를 항상 가동하여 가용가능한 상태로 두는 구성 방식이고,
Active-Standby는 일부 클러스터는 가동하고, 일부 클러스터는 대기 상태로 구성하는 방식이다.
상황에 따라 알맞은 구조를 선택하면 된다.
참고자료
- https://www.youtube.com/watch?v=y42TXZKFfqQ
- https://mangkyu.tistory.com/97
- https://silight.tistory.com/21
- https://okky.kr/article/230966
- https://bcho.tistory.com/1062
- https://blog.seulgi.kim/2015/05/what-is-mysql-replication.html
'프로젝트 > 프로젝트 관련' 카테고리의 다른 글
| Sticky Session, Session Clustering, Session Storage (0) | 2021.12.13 |
|---|---|
| Block vs Non-Block & Sync vs Async (0) | 2021.12.08 |
| Spring fox(Swagger) - API 문서화 (0) | 2021.12.05 |
| Scale Up, Sacle Out 서버 확장 (0) | 2021.12.05 |
| Redis란 무엇인가? (0) | 2021.12.01 |